




























Teil 2 – Übersetzung von „Phantom Virus: In search of Sars-CoV-2“(offGuardian)
[Teil 1 findest du hier]
Es gibt jedoch auch starke Anzeichen dafür, dass es sich bei den als SARS-CoV-2 bezeichneten Partikeln tatsächlich um harmlose oder sogar nützliche Partikel handelt, die als „extrazelluläre Vesikel“ (EVs) bezeichnet werden und extrem variable Abmessungen (von 20 bis 10.000 nm) aufweisen, sich jedoch zum größten Teil im Bereich von 20 nm bis 200 nm bewegen und die als Unterkategorie die „Exosomen“ umfassen.
Exosomen sind Partikel, die von unseren Zellen produziert werden und Nukleinsäuren, Lipide und Proteine enthalten. Sie sind an verschiedenen Aktivitäten beteiligt, die für unseren Körper nützlich sind, wie dem Transport von Immunmolekülen und Stammzellen sowie der Beseitigung der katabolen Ablagerungen der Zelle (Entgiftung).
Exosomen machen vielleicht den größten Anteil der EVs aus und sind seit über 50 Jahren Gegenstand zahlreicher Studien. Obwohl man bisher nur wenig von diesen nützlichen Partikeln gehört hat, ist die wissenschaftliche Literatur über sie riesig. Man findet sie allerdings nur auf PubMed. Wenn man hier „Exosom“ eingibt, werden über 14.000 Studien bereitgestellt! Wir können hier nicht näher auf EVs und Exosomen eingehen, aber es ist wichtig darauf hinzuweisen, dass sie nicht von Viren zu unterscheiden sind, und mehrere Wissenschaftler glauben, dass das, was als gefährliches Virus definiert wird, in Wirklichkeit nichts anderes als ein nützliches Exosom ist.
Exosomen sichtbar unter dem Elektronenmikroskop
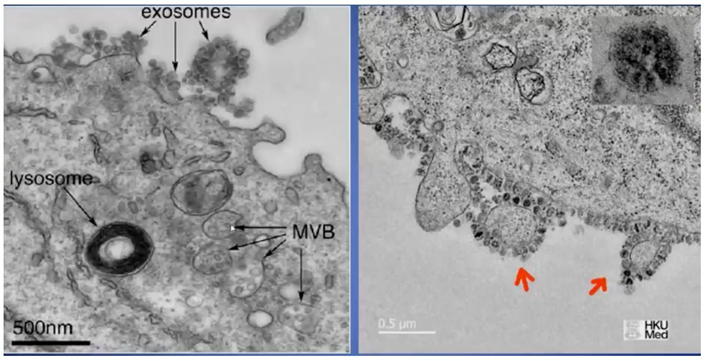
Wie auf obigen Bildern zu sehen ist, hat das größte der Exosomen die gleiche Größe und Struktur wie das angebliche SARS-CoV-2. Es ist daher leicht zu glauben, dass in dem großen Meer von Partikeln aus der bronchoalveolären Flüssigkeit des Patienten „Viren“ enthalten sind, die als SARS-CoV-2 bezeichnet werden und eigentlich nur Exosome sind.
Warum eine Partikelreinigung notwendig ist, um zu beweisen, dass Sars-Cov-2 existiert?
Wenn wir also eine Kultur mit unzähligen extrem ähnlichen Partikeln haben, muss die Partikelreinigung logischerweise der allererste Schritt sein, um die Partikel, von denen angenommen wird, dass sie Viren sind, wirklich als Viren definieren zu können. (Zusätzlich zur Partikelreinigung muss dann natürlich auch einwandfrei festgestellt werden, dass die Partikel beispielsweise unter realen und nicht nur unter Laborbedingungen bestimmte Krankheiten verursachen können.)
Wir haben diese beiden folgenden Fragen zahlreichen Vertretern der offiziellen Corona-Narrativen weltweit gestellt, aber niemand konnte sie beantworten:
- Wenn also nie eine Partikelreinigung durchgeführt wurde, wie kann man dann behaupten, dass die erhaltene RNA ein virales Genom ist?
- Wie kann eine solche RNA dann häufig zur Diagnose einer Infektion mit einem neuen Virus verwendet werden, sei es durch PCR-Tests oder auf andere Weise?
Wie schon oben erwähnt wurde, basiert die Tatsache, dass die RNA-Gensequenzen zu einem neuen pathogenen Virus namens SARS-CoV-2 gehören, nur auf dem Glauben, nicht auf Fakten! Für diese RNA-Gensequenzen, die von den Wissenschaftlern aus Gewebeproben für ihre In vitro Studien extrahiert wurden, wurden die sogenannten SARS-CoV-2-RT-PCR-Tests „kalibriert“!
Folglich kann nicht daraus geschlossen werden, dass die RNA-Gensequenzen, die aus den in diesen Studien hergestellten Gewebeproben „gezogen“ wurden und für die die PCR-Tests „kalibriert“ sind, zu einem bestimmten Virus gehören, nämlich wie in diesem Fall zu SARS-CoV-2.
Stattdessen wurde in allen Studien, in denen behauptet wurde, das Virus isoliert und sogar getestet zu haben, etwas ganz anderes getan: Die Forscher nahmen Proben aus dem Hals oder der Lunge von Patienten, zentrifugierten sie, um die größeren/schweren Molekülen von den kleineren/leichteren zu trennen und verwendeteten dann den Überstand, den oberen Teil des zentrifugierten Materials. Das nennen sie dann „Isolat“ und auf das wenden sie den PCR-Test an. Dieser Überstand enthält jedoch alle Arten von Molekülen, Milliarden verschiedener Mikro- und Nanopartikel, einschließlich der oben genannten extrazellulären Vesikel (EVs) und Exosomen, die von unserem eigenen Körper produziert werden und oft einfach nicht von Viren zu unterscheiden sind:
„Heutzutage ist es fast unmöglich, EVs und Viren durch kanonische Vesikelisolierungs-methoden wie differentielle Ultrazentrifugation zu trennen, da sie aufgrund ihrer ähnlichen Dimension häufig co-pelletiert werden,“ … wie es im Mai 2020 in der, in der Zeitschrift The Role of Extracelllular Vesicles a Allies of HIV, HCV and SARS Viruses, veröffentlichten Studie heißt.
Wissenschaftler „erschaffen“ das Virus also durch PCR: Sie nehmen Primer, d.h. zuvor vorhandene genetische Sequenzen, die in genetischen Banken verfügbar sind, modifizieren sie auf der Grundlage rein hypothetischer Überlegungen und bringen sie mit der auszentrifugierten Überstandsmasse in Kontakt, bis sie sich an eine RNA binden (Annelierung oder Fusion); dann transformieren sie durch das Reverse Transcriptase-Enzym die so „gefischte“ RNA in eine künstliche oder komplementäre DNA (cDNA), die dann und nur dann durch PCR erkannt und über eine bestimmte Anzahl von PCR-Zyklen multipliziert werden kann. (Jeder Zyklus verdoppelt die DNA-Menge. Aber je höher die Anzahl der Zyklen ist, die zur Herstellung von nachweisbarem „Virus“ -Material erforderlich ist, desto geringer ist die Zuverlässigkeit des PCR-Tests, was bedeutet, dass er tatsächlich alles Wichtige aus dem Überstand „herausholen“ kann. Bei über 25 Zyklen ist das Ergebnis in der Regel bedeutungslos. Doch alle aktuellen zirkulierenden PCR-Tests oder -Protokolle verwenden immer weit mehr als 25 Zyklen, in der Regel 35 bis 45!)
Um die Sache noch schlimmer zu machen, bestehen die Primer aus jeweils 18 bis 24 Basen (Nukleotiden). Das SARS-Cov2-Virus besteht angeblich aus 30.000 Basen. Der Primer repräsentiert also nur 0,08 Prozent des Virusgenoms. Dies macht es noch weniger möglich, das spezifische Virus, nach dem sie suchen, auf einem so winzigen Boden mit noch dazu Milliarden sehr ähnlicher Partikel zu finden.
Aber es geht noch weiter. Da das gesuchte Virus neu ist, gibt es eindeutig keine fertigen genetischen Primer, die der spezifischen Fraktion des neuen Virus entsprechen. Sie nehmen also Primer, von denen sie glauben, dass sie näher an der hypothetischen Virusstruktur liegen, aber es ist nur eine Vermutung. Wenn sie ihren Primer dann mit der Überstandsmasse vermischen, kann es sich an eines der Milliarden darin enthaltenen Moleküle anlagern. Dabei haben wir keine Ahnung, ob das, was sie so erzeugt haben, der Virus ist, nach dem sie suchen. Es ist jedoch in der Tat eine neue Kreation, kreiert von Forschern, die sie SARS-CoV-2 nennen und dabei gibt es keinerlei Verbindung zu dem vermuteten „echten“ Virus, das für die Krankheit verantwortlich ist.
Das „Virusgenom“ ist nichts anderes als ein Computermodell
Das gesamte Genom des SARS-CoV-2-Virus wurde nie sequenziert und stattdessen auf dem Computer „zusammengesetzt“. Der kalifornische Arzt Thomas Cowan nannte dies einen „wissenschaftlichen Betrug“. Und er ist bei weitem nicht der einzige!
Cowan schrieb am 15. Oktober 2020:
„Diese Woche machte mich meine Kollegin und Freundin Sally Fallon Morell auf einen erstaunlichen Artikel der CDC aufmerksam, der im Juni 2020 veröffentlicht wurde. In diesem Artikel ging es darum, dass eine Gruppe von etwa 20 Virologen den Stand der Wissenschaft in Bezug auf Isolierung, Reinigung und biologische Eigenschaften des neuen SARS-CoV-2-Virus beschrieben und diese Informationen an andere Wissenschaftler für ihre eigene Forschung weitergeben.
Eine gründliche und sorgfältige Überprüfung dieses wichtigen Papiers zeigt einige schockierende Ergebnisse.
Der Artikelabschnitt mit der Unterüberschrift „Whole Genome Sequencing“ zeigte, dass „anstatt das Virus isoliert und das Genom von Ende zu Ende sequenziert zu haben“, die CDC „37 Paare verschachtelte PCRs entwarf, die das Genom nach der Grundlage der Coronavirus-Referenz sequenzierten.“ (GenBank-Zugangsnummer NC045512).“
Man kann sich also fragen, wie sie denn das Virus sequenziert haben, d.h. wie haben sie es genetisch analysiert?
Nun, sie analysierten nicht das gesamte Genom, sondern nahmen einige in den Kulturen gefundene Sequenzen, behaupteten ohne Beweis, dass sie zu einem neuen spezifischen Virus gehörten, und machten dann eine Art genetisches Computer-Puzzle, um den Rest zu füllen. „Sie verwenden die Computermodellierung, um im Wesentlichen nur ein Genom von Grund auf neu zu erstellen“, sagt der Molekularbiologe Andrew Kaufman.
Somit ist es auch keine Überraschung, dass der vom Pasteur-Institut entwickelte Primer des Tests genau einer Sequenz von Chromosom 8 des menschlichen Genoms entspricht.
Quelle: offGuardian – Teil 3 kommt demnächst!
Alles Liebe
Andrea Viertl









{kind=link}